In this section
Please note: while we do not claim that our datasets for all six of our textual traditions are complete, we currently offer data relating to over 90 % of known manuscripts of Guiron le courtois, the Histoire ancienne, the Roman de Troie, and the Tristan en prose. Data entry for the Lancelot en prose and the Roman d'Alexandre is ongoing, and currently more than 80% complete for the Lancelot. In the meantime, searches relating to the Roman d'Alexandre and the Lancelot en prose will necessarily give incomplete results, which may be in need of further editing. If you spot any errors or have any comments, we could be very grateful if you could send us an email using the contact tab on the menu bar.
×Explore
") MS Directory
MS Directory
Use the MS Directory to see an ordered list of all manuscripts in the database. The list allows you to link to the full manuscript record or to select a range of manuscript parts to compare based on their physical characteristics.
Map search
The map-based search allows you to narrow your results within a set of manuscript parts returned from an earlier search. You can filter according to the textual traditions represented, the manuscript parts' place of origin, places to which they have been historically linked, or the language varieties found in them. You can also narrow your selection by specifiying a date range for the date of production.
The results will be mapped to show the library in which the manuscript is currently housed and, where possible, the place of origin and any recorded places of provenance. Hovering over a marker on the map will make other markers related to that manuscript part more prominent, for easy identification. Selecting a marker will reveal more information about that location.
Textual tradition search
The textual tradition search allows you to assemble an ordered sequence of narrative segments relating to a textual tradition. If you modify the list, you will be presented with a list of other manuscripts in the database that share the narrative content in the sequence defined.
The count of the longest overlapping sequence of consecutive narrative segments will be shown, and also the longest overlapping sequence of narrative segments that share a source variant.
Database structure
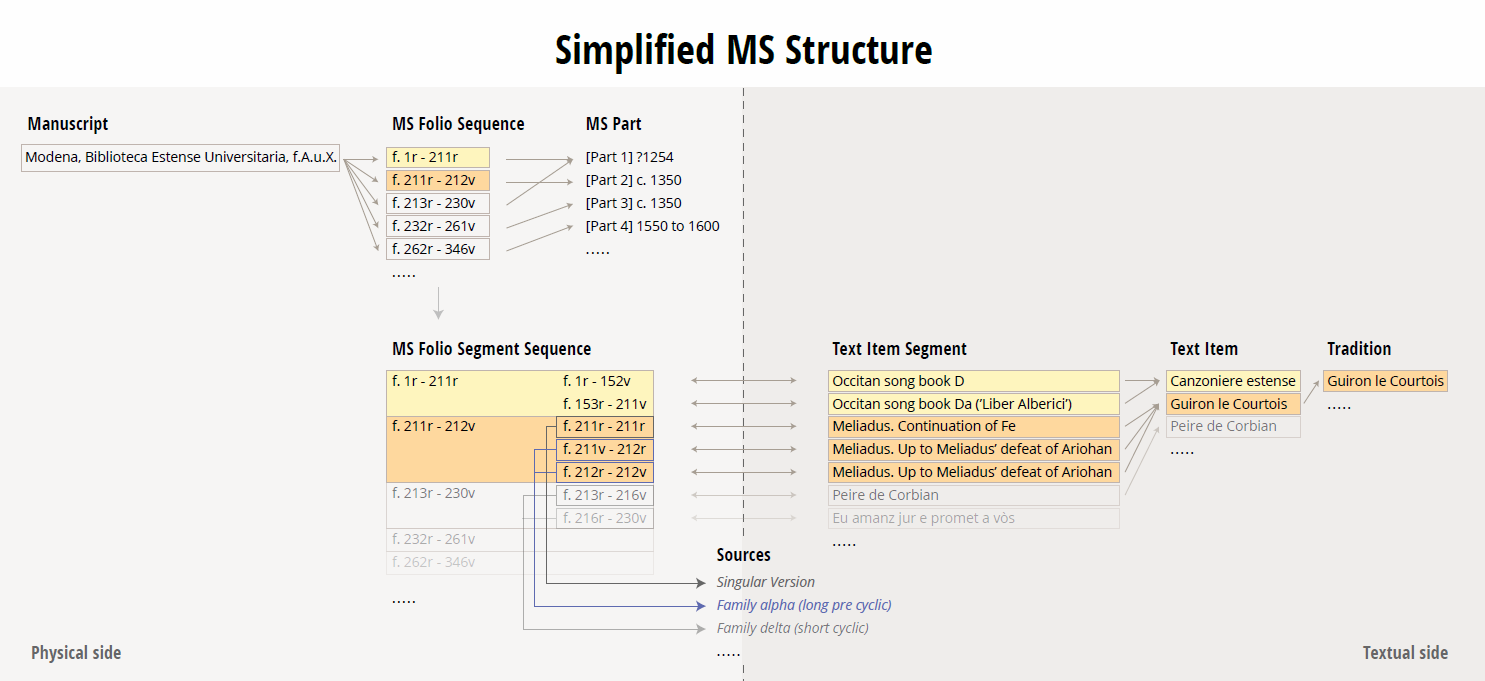
Each manuscript is divided into Folio Sequences which belong to a MS Part. This structure allows for insertions of folios from different parts (for instance, where a page in a manuscript has been lost, and a replacement page added at a later date). The Folio Sequences contain one or more Folio Segment Sequences, usually corresponding to a narrative episode identified in the project segmentation as a Text Item Segment (although the segmentation of the Roman de Troie follows a different model). Each occurence of a segment is associated with a particular Source or redaction of the text. On the textual side, and moving from the smallest unit to the largest grouping, a Text Item Segment will belong to a Text Item, which in turn will usually be associated with a particular Textual Tradition.
A simplified version of the structure is shown in the diagram below; for the sake of clarity, many database objects are omitted.
(NB. This diagram is illustrative only and does not present an actual example. Click to enlarge)